Fast-dLLM++: Fréchet Profile Decoding
for Faster Diffusion LLM Inference
A profile-aware, training-free decoder for masked diffusion language models. Replaces Fast-dLLM's weakest-token rule with a Fréchet certificate over the full confidence profile, recovering up to 37% throughput at comparable accuracy.
TL;DR
Diffusion LLMs promise parallel generation but are bottlenecked by deciding which masked tokens to commit together. Fast-dLLM's confidence-aware rule is conservative because it compresses each candidate set to its single weakest token. Fast-dLLM++ replaces that rule with a sharp distribution-free certificate built on the full sorted confidence profile. It is provably stronger than the weakest-token rule, recovers it exactly when confidences are flat, and adds a measurable heterogeneity bonus the moment they are not.
Core idea
Fréchet profile decoding
Use the full sorted confidence profile, not just the weakest selected token.
Theory
Sharpest marginal certificate
Distribution-free Fréchet–Hoeffding lower bound on joint correctness.
Method
Drop-in replacement
No model changes, no extra cache, no training. Sort + prefix sum.
Outcome
Up to 1.41× throughput
Up to 32% NFE reduction on LLaDA-8B at comparable accuracy.
Why parallel diffusion decoding is hard
Masked diffusion language models like LLaDA and Dream generate text by iteratively unmasking tokens from a fully masked sequence. Unlike autoregressive models, they can in principle decode many positions at once, which is the entire reason they are interesting for inference. The catch: if you unmask too many positions in parallel from independent marginals, the resulting combination is incoherent even when each individual token looks confident. This is the curse of parallelism, and every diffusion decoder must trade off against it.
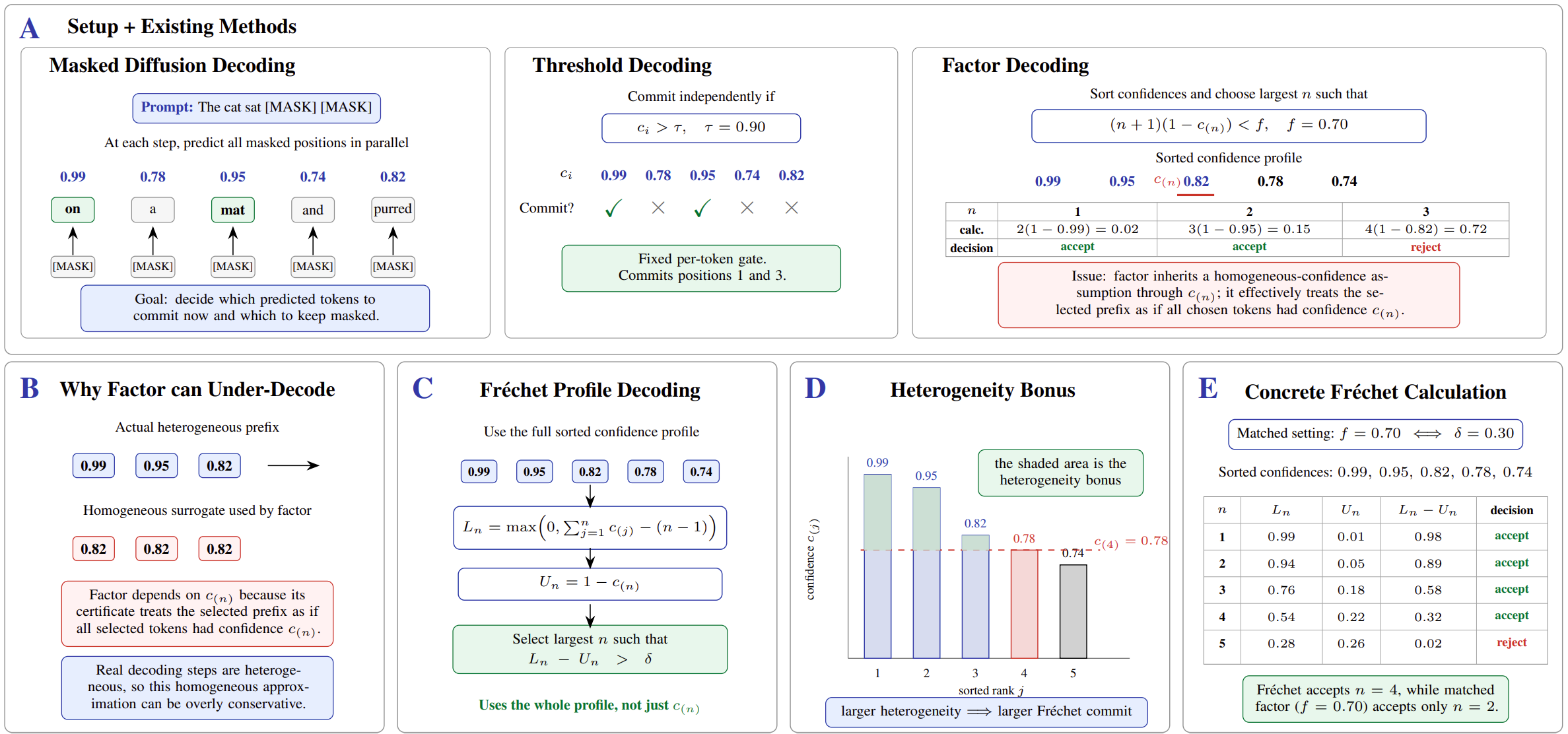
Threshold and factor rules leave speed on the table
Fast-dLLM's factor rule accepts $n$ tokens whenever $(n+1)(1-c_{(n)}) < f$, where $c_{(n)}$ is the weakest confidence among the top-$n$ candidates. That single number controls the entire decision. If even one selected token has middling confidence, every other near-certain token gets held back with it.
Real confidence profiles are heterogeneous
In practice, a diffusion step rarely hands you a flat profile. You typically have a few near-certain tokens (function words, repeated identifiers, arithmetic carries already resolved) sitting next to a few moderately confident ones. Compressing that profile to a scalar throws away the cheapest-to-certify parallelism in the batch.
What the full profile actually buys you
Take the sorted confidences $(c_{(1)}, \ldots, c_{(n)})$. The classical Fréchet–Hoeffding/Bonferroni lower bound says the probability that all $n$ argmax tokens are jointly correct is at least $L_n = \max\{0, \sum c_{(j)} - (n-1)\}$. Any competing tuple disagrees in at least one position, so its probability is at most $U_n = 1 - c_{(n)}$. Commit the largest prefix where $L_n - U_n > \delta$. That is the entire selector.
Method in one paragraph
At each denoising step, sort the masked-position confidences $c_{(1)} \ge c_{(2)} \ge \cdots \ge c_{(m)}$. For each prefix size $n$, compute the Fréchet lower bound $L_n$ on the probability that the marginal-greedy tokens are all simultaneously correct, the upper bound $U_n$ on any competitor, and their margin $G_n = L_n - U_n$. Commit the largest $n$ with $G_n > \delta$.
That is it — sort once, prefix-sum once, scan once. No model change, no extra cache, no training. Drop in next to any Fast-dLLM cache mode.
Theory in three results
(1) Greedy equivalence. If $L_n > U_n$, then the marginal-greedy tuple is the unique mode of the true joint conditional distribution. So the parallel commit matches the joint greedy decision, even though we never computed the joint.
(2) Reduction to factor. When all selected confidences are equal, the Fréchet criterion reduces exactly to Fast-dLLM factor decoding under the parameter mapping $f = 1 - \delta$. So Fast-dLLM++ is a strict generalization, not a sideways method.
(3) Heterogeneity bonus. The Fréchet score decomposes as $G_n = F_n + B_n$, where $F_n$ is the weakest-token factor core and $B_n \ge 0$ is the area between the actual profile and the $c_{(n)}$ floor. The bonus is exactly the parallelism that factor decoding was discarding.
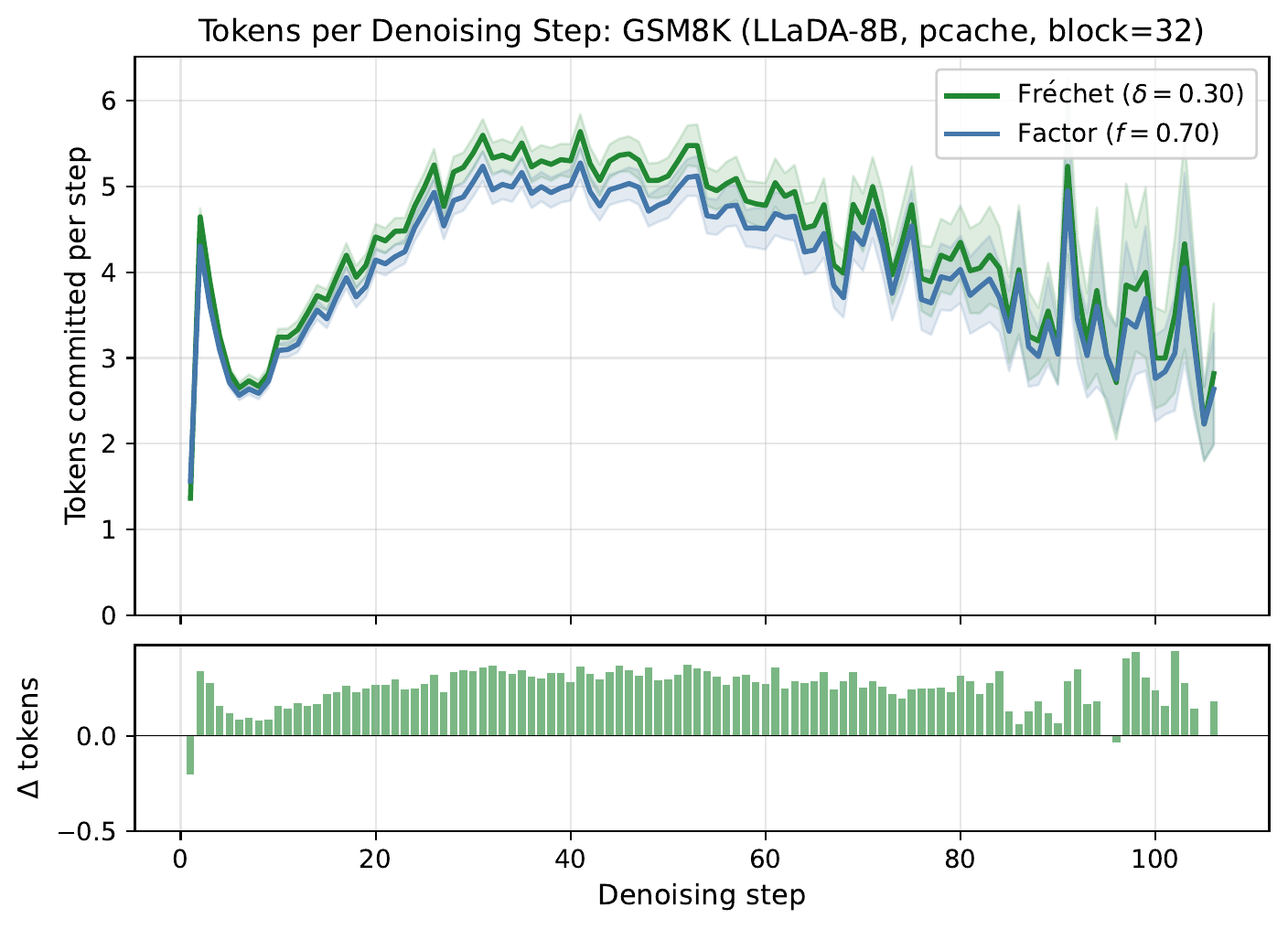
The bonus shows up at the step level. On GSM8K with LLaDA-8B, Fréchet commits more tokens per denoising step than matched factor at every step. Those extra tokens accumulate over the trajectory and turn into the throughput gain reported below.
Headline numbers on LLaDA-8B
Eight settings: GSM8K, MATH, HumanEval, MBPP at generation lengths 256 and 512, all on LLaDA-8B-Instruct with PrefixCache and block size 32 on a single H100. Speedups and NFE reductions are versus Fast-dLLM threshold decoding ($\tau = 0.9$), the state-of-the-art baseline. Fréchet uses margin $\delta = 0.25$ as a single global operating point, never tuned per task.
Average over all 8 settings
1.36× throughput, 29.2% fewer NFE
One global setting, eight benchmarks. Average accuracy change is a 0.48-point delta — well within run-to-run noise on these tasks.
GSM8K, gen length 256
1.41× throughput, 32.0% fewer NFE
From 73.8 → 103.8 tokens/s. Accuracy moves from 77.6 → 77.2. The heterogeneity bonus is largest on reasoning where confident filler sits next to less-certain reasoning steps.
HumanEval, gen length 512
1.40× throughput, 30.9% fewer NFE
From 54.1 → 75.5 tokens/s with pass@1 essentially unchanged (41.5 → 41.5). Code generation produces strongly heterogeneous profiles, which is exactly the regime where $B_n$ is largest.
vs full-step LLaDA baseline
4.31× throughput, 79.1% fewer NFE
Compounding the cache + selector improvements, Fast-dLLM++ delivers a 4× wall-clock speedup over vanilla LLaDA-8B decoding while preserving accuracy.
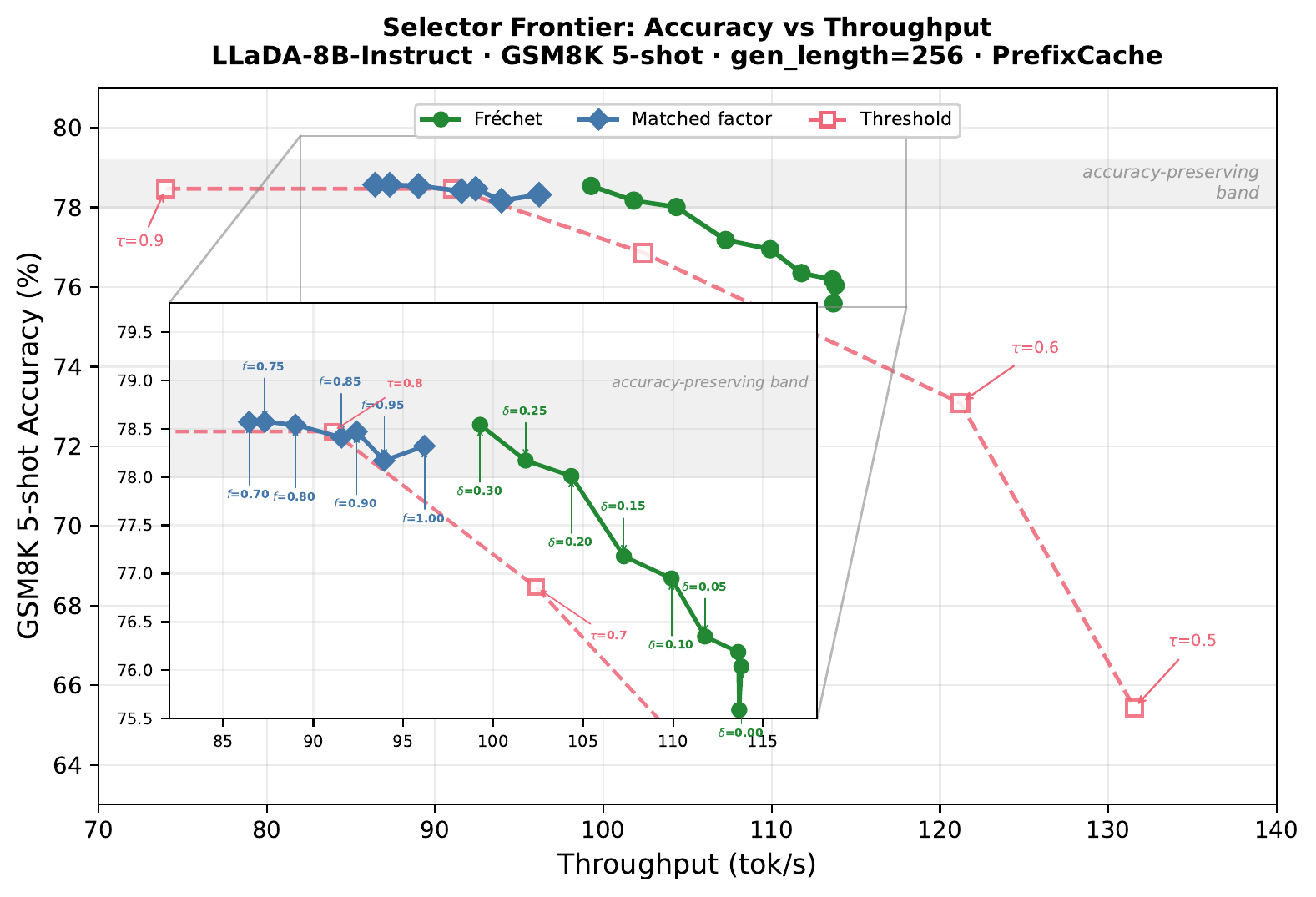
The frontier shifts, not just a single point. Sweeping the selector parameter (Fréchet $\delta$, matched factor $f = 1-\delta$, threshold $\tau$) shows that Fréchet is not just better at one operating point — it shifts the entire matched-factor frontier toward higher throughput at comparable accuracy.
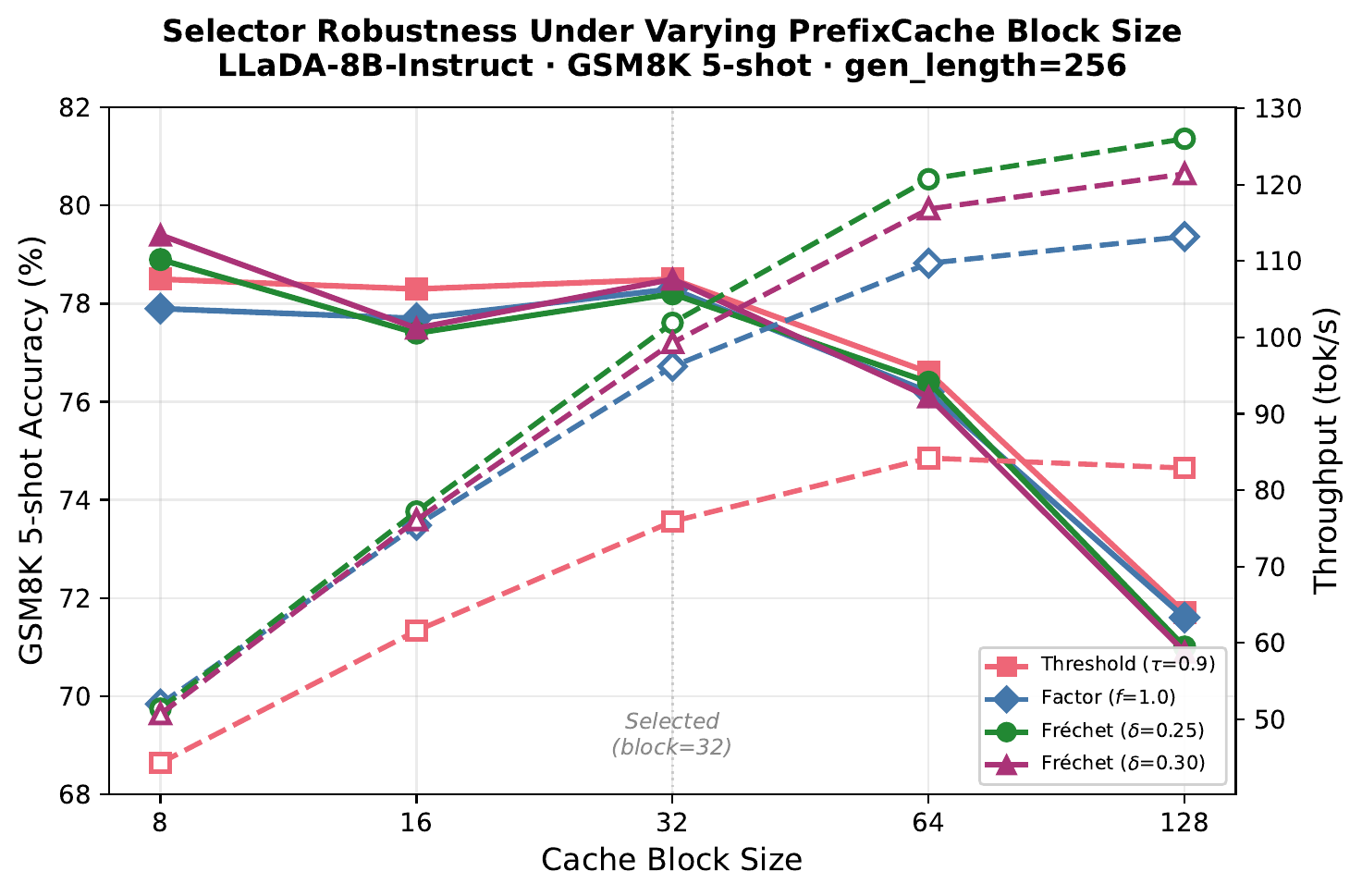
Stable across block sizes. The advantage is not a knife-edge tuning result. Across block sizes 8 to 64, Fréchet matches or beats factor and threshold on both throughput and accuracy.
Reading the results
The most important practical message is that the bottleneck in confidence-aware diffusion decoding is the selector, not the model or the cache. Fast-dLLM already showed that KV caching plus a confidence rule beats vanilla iterative unmasking. Fast-dLLM++ shows that within the confidence-rule family, you can get another 30 percent off the NFE budget for free, just by using the rest of the profile that factor decoding throws away.
A second observation is that the heterogeneity bonus scales with generation length. On GSM8K at length 1024, Fréchet still beats factor across every cache mode — the gain does not decay as the trajectory gets longer.
A third one: the method generalizes. On the diffusion multimodal LLaDA-V model, Fréchet pushes MathVista throughput from 9.9× to 11.6× over full-step decoding while slightly improving accuracy. On the diffusion LM Dream-v0-Base-7B, it delivers 1.28× average throughput with 21.1% NFE reduction over threshold. The selector is not specific to one model family.
Practical takeaways
If you ship Fast-dLLM, swap the selector
It is two lines of code: sort, prefix-sum, scan for the largest $n$ with $G_n > \delta$. No new caches, no retraining, no risk of breaking parity with the original model.
Use $\delta = 0.25$ unless you have a reason
One global operating point clears the eight LLaDA-8B settings reported above. Tasks with strong heterogeneity (HumanEval, MBPP) tolerate a smaller margin; chain-of-thought reasoning prefers a slightly tighter one. The sweep is mild.
Fréchet is the marginal-only ceiling
Without estimating dependence between tokens, Fréchet is the strongest distribution-free certificate available from per-token confidences. To go further, you need a real dependence estimate — the paper sketches a stability extension that uses total variation between the joint and the product approximation.
Why this matters for the industry
Diffusion LLMs are at the same crossroads autoregressive LLMs were at before speculative decoding became standard. The models exist, the quality is competitive, but inference is bottlenecked by the decoding rule, not the network. Every provider that wants to serve diffusion LLMs at scale will eventually run into the curse of parallelism, and every selector they ship will sit somewhere on the throughput–accuracy frontier we plot above.
Fast-dLLM++ moves that frontier to the right with a one-page change. It does not require a new model, a new cache implementation, a new training run, or even a new hyperparameter beyond the existing factor knob. For teams already running Fast-dLLM with PrefixCache or DualCache, the switching cost is the time it takes to re-run benchmarks. For teams writing a new diffusion serving stack, the right default is the profile-aware certificate, not the weakest-token rule.
The broader take: in confidence-aware decoding, the marginal information you collect per step is a richer signal than current selectors use. Fast-dLLM++ exploits that within a single forward pass; the obvious next step is to combine profile certificates with light-weight dependence estimation, which the theory suggests can certify additional parallel commits even when Fréchet alone is too conservative.
BibTeX
@inproceedings{kasa2026fastdllmpp,
title = {Fast-dLLM++: Fr\'{e}chet Profile Decoding for Faster Diffusion LLM Inference},
author = {Kasa, Siva Rajesh and Dai, Yasong and Negi, Sumit and Li, Hongdong},
booktitle = {ICML 2026 Workshop on Structured Probabilistic Inference and Generative Modeling (SPIGM)},
year = {2026},
eprint = {2606.02955},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2606.02955}
}